지금까지 LSTM 계층의 마지막 은닉 상태만을 Decoder에 전달했다. 그러나 Encoder 출력의 길이는 입력 문장의 길이에 따라 바꿔주는 게 좋다. 이 점이 Encoder의 개선 포인트이다.
위의 그림처럼 시각별 LSTM 계층의 은닉 상태 벡터를 모두 이용하는 것이다.
각 시각의 은닉 상태 벡터를 모두 이용하면 입력된 단어와 같은 수의 벡터를 얻을 수 있다. 위의 예에서는 5개의 단어가 입력되었고, 이때 Encoder는 5개의 벡터를 출력한다. 이것으로 Encoder는 '하나의 고정 길이 벡터'라는 제약으로부터 해방된다.
위의 그림에서 주목할 것은 LSTM 계층의 은닉 상태의 "내용"이다. 시각별 LSTM 계층의 은닉 상태에는 어떠한 정보가 담겨 있을까? 각 시각의 은닉 상태에는 직전에 입력된 단어에 대한 정보가 많이 포함되어 있다는 사실이다.
Encoder가 출력하는 hs 행렬은 각 단어에 해당하는 벡터들의 집합이라고 볼 수 있다.
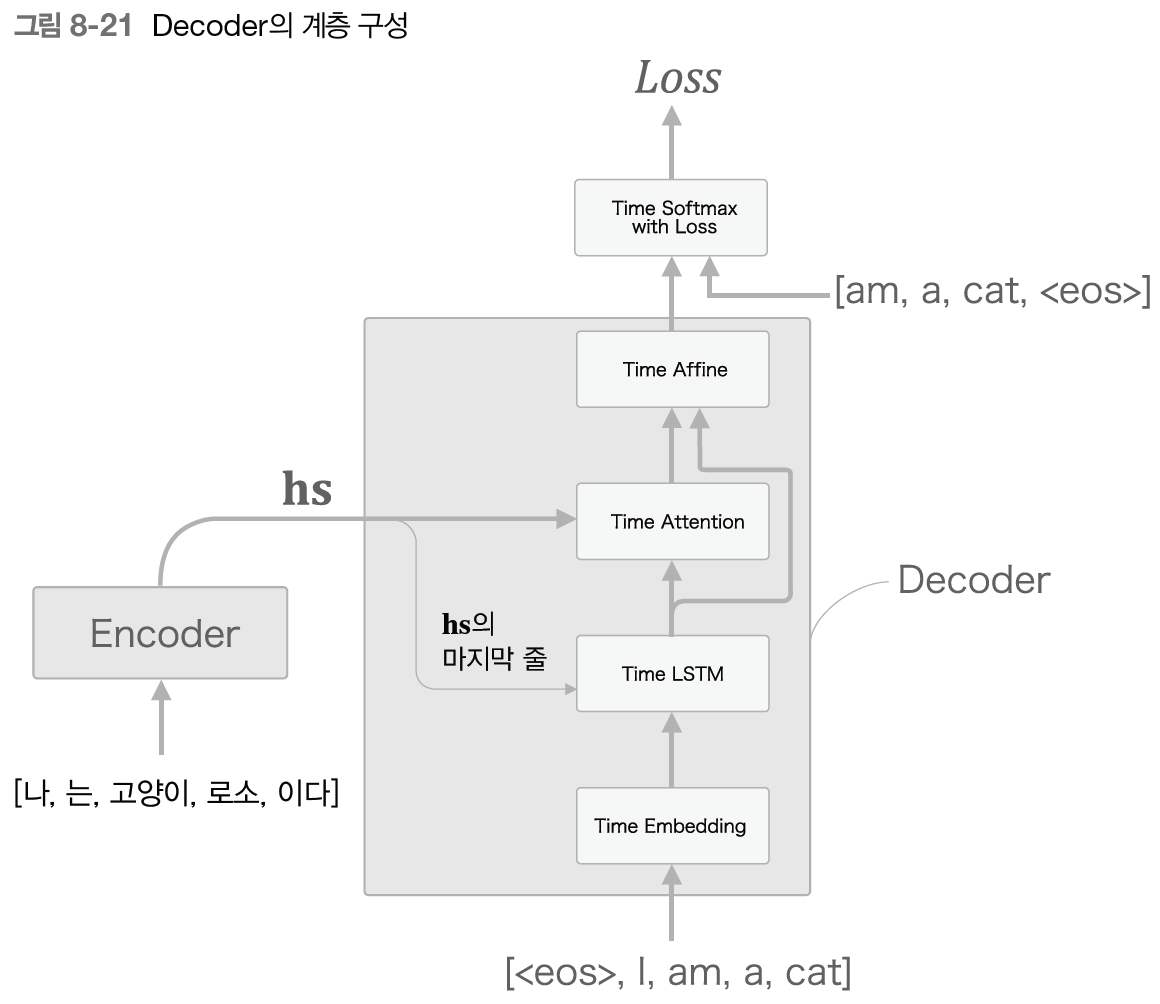
Decoder 개선①
Encoder는 각 단어에 대응하는 LSTM 계층의 은닉 상태 벡터를 hs로 모아 출력한다. 그리고 이 hs가 Decoder에 전달되어 시계열 변환이 이뤄진다.
앞에서 본 가장 단순한 seq2seq에서는 Encoder의 마지막 은닉 상태 벡터만을 Decoder에 넘겼다.
Decoder는 Encoder의 LSTM 계층의 마지막 은닉 상태만을 이용한다. hs에서 마지막 줄만 빼내어 Decoder에 전달한 것이다.
그렇다면 이 hs 전부를 활용할 수 있도록 Decoder를 개선해 볼 것이다.
목표는 "도착어 단어"와 대응 관계에 있는 "출발어 단어"의 정보를 골라내는 것과 그 정보를 이용하여 번역을 수행하는 것이다. 이 구조를어텐션이라 부른다.
8.2 어텐션을 갖춘 seq2seq 구현
encoder: 모든 은닉 상태 반환
decoder: 순전파, 역전파, 새로운 문장 생성 / attention 계층 연결
8.3 어텐션 평가
날짜 형식 변경하는 문제 테스트 - 입력과 출력에 년,월,일 대응 관계 존재 -> 어텐션이 올바르게 주목하는지 확인 가능
학습 결과 및 어텐션 시각화
어텐션에서는 모델의 처리 논리가 인간의 논리를 따르는지를 판단 가능
8.4 어텐션에 관한 남은 이야기
양방향 RNN - 단어의 주변 정보를 균형있게
-구현 방법 중 한 가지는 2개의 LSTM 계층을 준비한 후 입력 단어의 순서를 조정
attention 계층의 위치
- 앞 절에서 본 계층 구성이 좀 더 구현하기 쉬움, 쉽게 모듈화 가능
seq2seq 심층화 - LSTM 계층을 깊게 쌓으면 표현력 높은 모델 쌓을 수 있음 - 일반적으로 encoder와 decoder에서 같은 층수의 lstm 사용 - 계층을 깊게 할 때는 일반화 성능을 떨어뜨리기 않기 위해 드롭아웃, 가중치 공유 등 사용
skip 연결(잔차 연결, 숏컷) - 층을 깊게 할 때 사용되는 중요한 기법 - 계층을 넘어 선을 연결, 계층을 건너뛴다 - 접속부에서 원소별 덧셈 -> 역전파 시 기울기를 그대로 흘려보내므로 기울기 손실/폭발 위험성 줄여 좋은 학습 가능 - RNN 시간 방향에서 기울기 소실: 게이트 달린 RNN, 기울기 폭발: 기울기 클리핑, RNN 깊이 방향 기울기 소실: skip 연결 효과적