7.1 언어 모델을 사용한 문장 생성

시계열 데이터를 한꺼번에 처리하는 Time 계층 사용한 구성
언어 모델은 위와 같이 다음에 출현할 단어의 확률 분포를 출력
다음 단어를 새로 생성하려면?
첫번째로는 확률이 가장 높은 단어 선택
확률분포에서 샘플링한 결과 'say'가 선택된 경우
하지만 이 선택은 확률적이기 때문에 필연적이지는 않는다
즉, 낮은 확률로 다른 단어가 선택될수도 있다는 점
import sys
sys.path.append('..')
from rnnlm_gen import RnnlmGen
from dataset import ptb
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
model.load_params('../ch06/Rnnlm.pkl')
# start 문자와 skip 문자 설정
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
# 문장 생성
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print(txt)문장을 생성하는 코드
7.2 seq2seq
seq2seq는 2개의 RNN을 이용해서 시계열 데이터를 다른 시계열 데이터로 변환하는 모델
원리
- 하나의 RNN이 입력 데이터를 Encoding하고 다른 RNN이 데이터를 Decoding하기 때문에 Encoder - Decoder 모델이라고도 불린다.
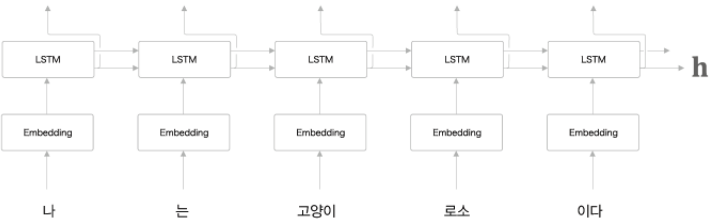
Encoder는 RNN을 이용해 시계열 데이터를 h라는 은닉 상태 vector로 변환
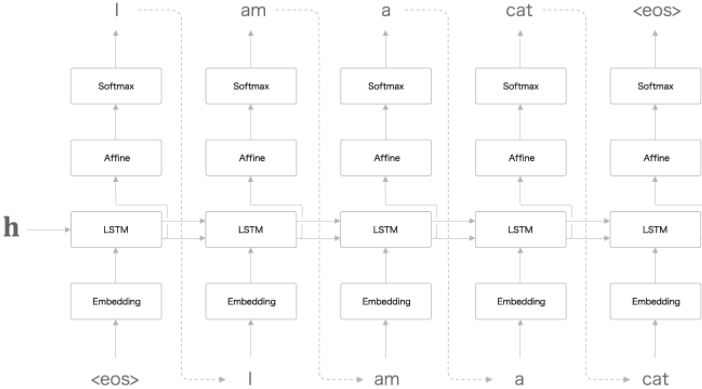
Decoder의 계층
7.3 seq2seq 구현
Encoder 구현
import sys
sys.path.append('..')
from common.time_layers import *
from common.base_model import BaseModel
class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :]
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return doutDecoder 구현
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh7.4 seq2seq 개선
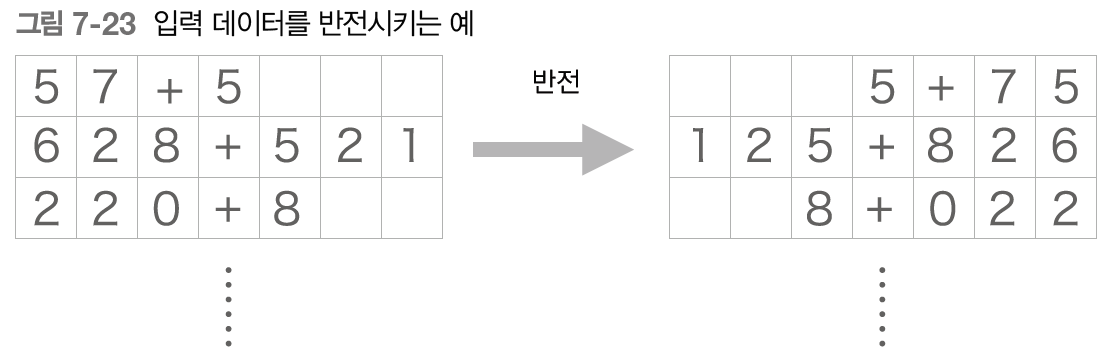
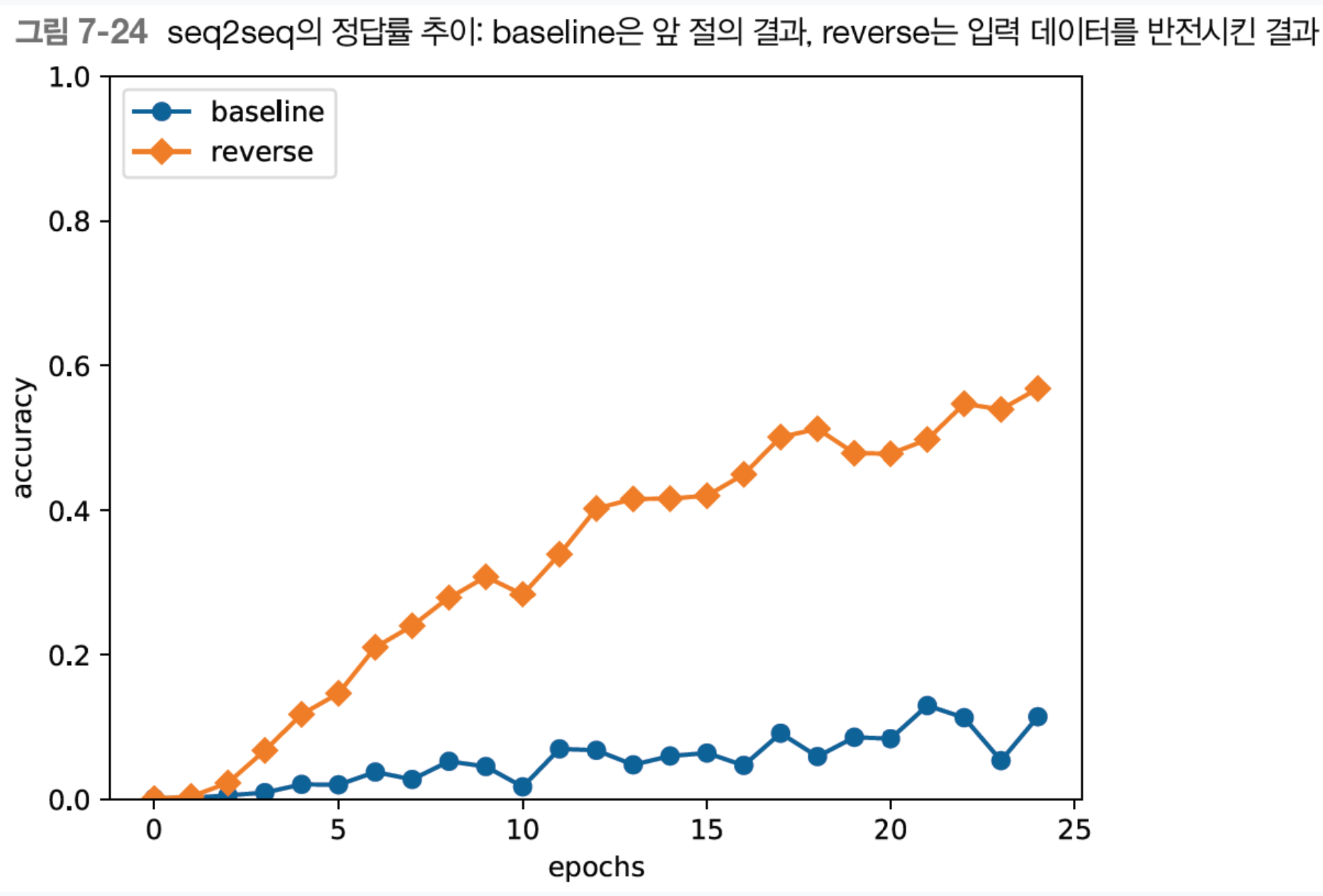
첫번째 개선안: 입력 데이터 반전
결과
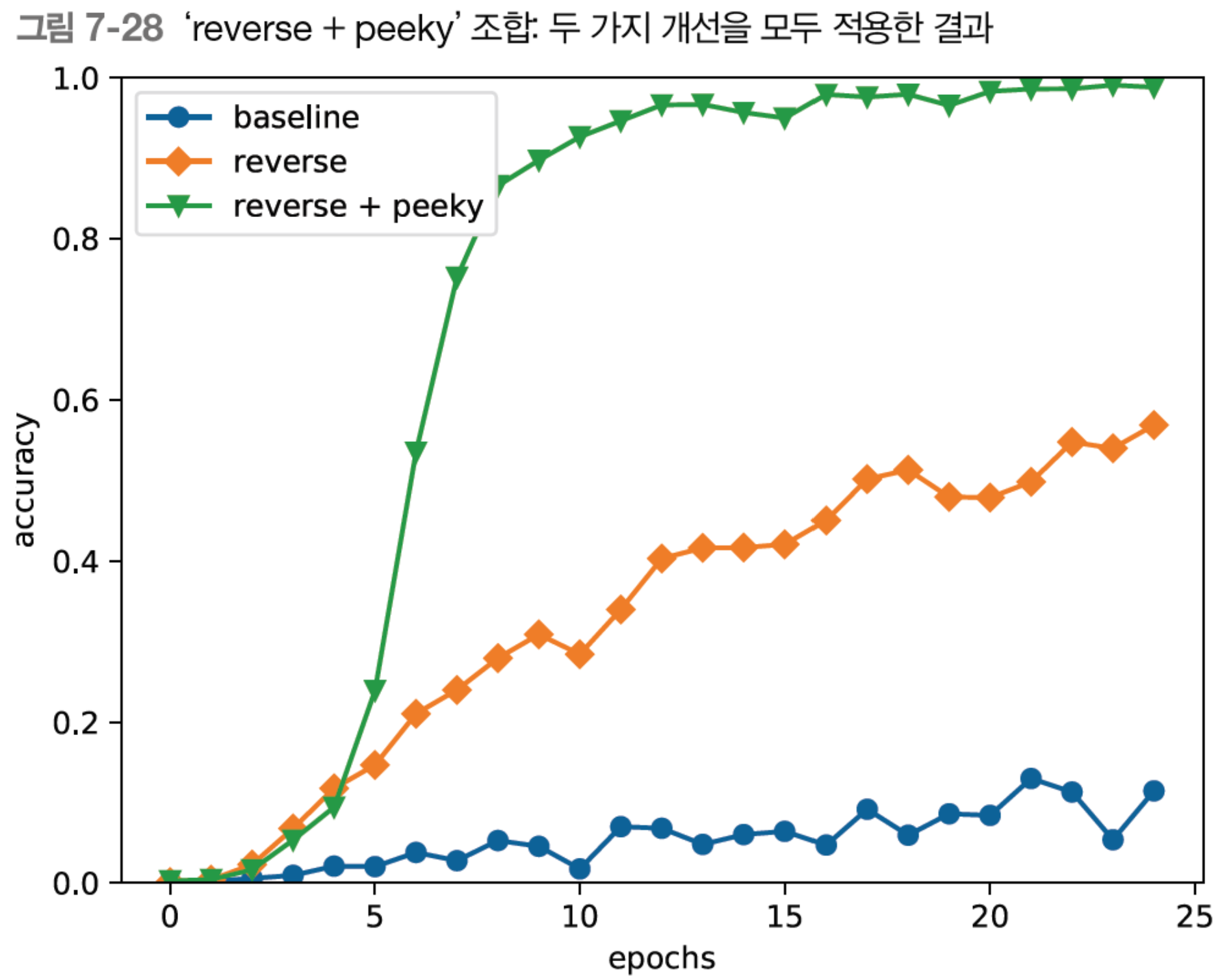
두번째 개선안: Peeky
class PeekyDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(H + D, 4 * H) / np.sqrt(H + D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H + H, V) / np.sqrt(H + H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
self.cache = None
def forward(self, xs, h):
N, T = xs.shape
N, H = h.shape
self.lstm.set_state(h)
out = self.embed.forward(xs)
hs = np.repeat(h, T, axis=0).reshape(N, T, H)
out = np.concatenate((hs, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((hs, out), axis=2)
score = self.affine.forward(out)
self.cache = H
return score
def backward(self, dscore):
H = self.cache
dout = self.affine.backward(dscore)
dout, dhs0 = dout[:, :, H:], dout[:, :, :H]
dout = self.lstm.backward(dout)
dembed, dhs1 = dout[:, :, H:], dout[:, :, :H]
self.embed.backward(dembed)
dhs = dhs0 + dhs1
dh = self.lstm.dh + np.sum(dhs, axis=1)
return dh
def generate(self, h, start_id, sample_size):
sampled = []
char_id = start_id
self.lstm.set_state(h)
H = h.shape[1]
peeky_h = h.reshape(1, 1, H)
for _ in range(sample_size):
x = np.array([char_id]).reshape((1, 1))
out = self.embed.forward(x)
out = np.concatenate((peeky_h, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((peeky_h, out), axis=2)
score = self.affine.forward(out)
char_id = np.argmax(score.flatten())
sampled.append(char_id)
return sampledclass PeekySeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = PeekyDecoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads결과
'독서 > 밑바닥부터 시작하는 딥러닝 2' 카테고리의 다른 글
| [밑바닥부터 시작하는 딥러닝 2]Chapter 8. 어텐션 (0) | 2024.08.11 |
|---|---|
| [밑바닥부터 시작하는 딥러닝 2]Chapter 6. 게이트가 추가된 RNN (0) | 2024.07.30 |
| [밑바닥부터 시작하는 딥러닝 2] Chapter 5. 순환 신경망(RNN) (6) | 2024.07.23 |
| [밑바닥부터 시작하는 딥러닝 2] Chapter 4. word2vec 속도개선 (0) | 2024.07.14 |
| [밑바닥부터 시작하는 딥러닝 2] Chapter 3. word2vec (0) | 2024.07.07 |