6.1 RNN의 문제점
BPTT에서의 vanishing gradient , exploding gradient 으로 인해 시계열 데이터의 장기 의존 관계 학습에 어려움이 있다.
RNN - 시계열 데이터 xt𝑥𝑡 입력시 htℎ𝑡(은닉 상태) 출력
기울기(gradient)
- 학습해야 할 의미가 있는 정보
- 과거로 전달, 장기 의존 관계 학습
- 중간에 정보가 사라지면 가중치 매개변수의 갱신 불가
6.1.2 기울기 소실( vanishing gradient ), 기울기 폭발( exploding gradient )의 원인
- 기울기 소실 - 기울기가 빠르게 작아지며 일정 수준 이하로 작아지면 가중치 매개변수가 갱신되지 않는 문제
- 기울기 폭발 - 오버플로를 유발하여 NaN(Not a Number) 유발
- 해결 방법
- 기울기 클리핑(gradients clipping)
- 모든 매개변수에 대해 하나의 기울기로 처리한다고 가정 이를 g^𝑔^로 표기
- threshold를 문턱값으로 설정
- 기울기의 L2노름 ||g^𝑔^|| 이 문턱값 초과시 기울기 수정
- 기울기 클리핑(gradients clipping)
- 해결 방법
원인 1 : tanh ( y = tanh(x) )

RNN에서의 기울기 전파
위 그림처럼 RNN에서 역전파는 tanh, MatMul 연산을 통과한다
이 중 tanh의 값과 미분 값을 그래프로 그리면
점선 - 미분
tanh의 값은 1.0이하의 값이며 역전파에서 기울기가 tanh노드를 지날 때마다 값이 계속 작아진다. (vanishing gradient)
원인 2 : MatMul(행렬 곱)
행렬 곱에 주목한 역전파의 기울기
dh라는 기울기가 지나간다고 했을 때, MataMul 에서 dhWTh𝑑ℎ𝑊ℎ𝑇 행렬 곱으로 기울기 계산( 시계열 데이터의 길이만큼 반복하여 ) -> 시간 크기에 비례하여 기울기 증가
-> exploding gradient -> 오버플로 -> NaN 발생
6.2 기울기 소실과 LSTM
게이트가 추가된 RNN
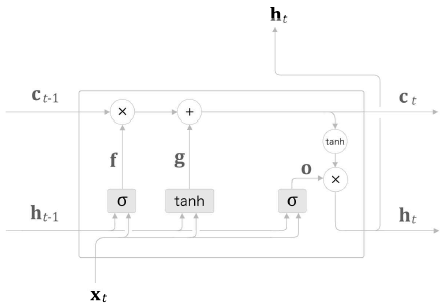
RNN, LSTM의 비교(LSTM 계층에 c를 memory cell 이라 부른다.)
memory cell - 자기 자신으로만 주고받는 특징을 가진 경로(LSTM 계층 내)
LSTM의 hidden state - h는 다른 계층으로 출력
시각 t에서의 기억이 저장되어 있는 ct𝑐𝑡의 정보를 활용해 외부 계층에 h_t(memory cell의 값을 tanh 함수로 변환한 값) 출력
memory cell 활용, hidden state htℎ𝑡 계산
게이트(gate) - 데이터의 흐름을 제어하는 역할
output gate - hidden state의 출력 담당하는 게이트
( 입력 xt𝑥𝑡와 이전 상태 ht−1ℎ𝑡−1를 활용하여 아래 식으로 계산 )
o=σ(xtW(o)x+ht−1W(o)h+b(o))𝑜=𝜎(𝑥𝑡𝑊𝑥(𝑜)+ℎ𝑡−1𝑊ℎ(𝑜)+𝑏(𝑜))
- 게이트 임을 표시하기 위해 o 첨자 사용
- σ𝜎 - 시그모이드 함수
- 입력 xt𝑥𝑡에 가중치 W(o)x𝑊𝑥(𝑜), 이전 시각의 hidden state ht−1ℎ𝑡−1에 가중치 W(o)h𝑊ℎ(𝑜) 행렬들의 곱, 편향 b(o)𝑏(𝑜) 를 모두 더한 후 시그모이드 함수를 거쳐 출력 게이트의 o 출력
forget gate - 불필요한 기억을 잊도록 하는 게이트
f=σ(xtW(f)x+ht−1W(f)h+b(f))𝑓=𝜎(𝑥𝑡𝑊𝑥(𝑓)+ℎ𝑡−1𝑊ℎ(𝑓)+𝑏(𝑓))
위의 식을 실행하여 forget 게이트의 출력 f를 구하며 이전 기억 셀인 ct−1𝑐𝑡−1과의 원소별 곱, ct=f⊙ct−1𝑐𝑡=𝑓⊙𝑐𝑡−1을 계산하여 ct𝑐𝑡 를 구함
새로운 기억 셀
새로운 정보 추가를 위해 tanh노드 추가, 계산하여 ct−1𝑐𝑡−1에 더함
g=tanh(xtW(g)x+ht−1W(g)h+b(g))𝑔=𝑡𝑎𝑛ℎ(𝑥𝑡𝑊𝑥(𝑔)+ℎ𝑡−1𝑊ℎ(𝑔)+𝑏(𝑔)) 의 수식으로 계산된다.
g(기억 셀에 추가하는 새로운 기억)에 이전 시각 ct−1𝑐𝑡−1 을 더해 새로운 기억 생성
input gate - g에 게이트 추가
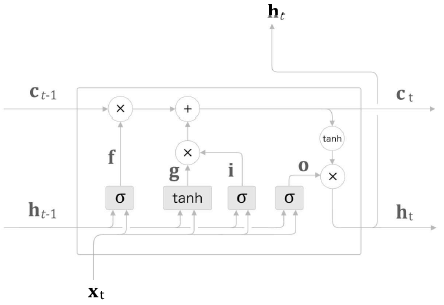
g의 각 원소(추가되는 정보)의 가치가 얼마나 큰지에 대한 판단하기 위한 역할
i=σ(xtW(i)x+ht−1W(i)h+b(i))𝑖=𝜎(𝑥𝑡𝑊𝑥(𝑖)+ℎ𝑡−1𝑊ℎ(𝑖)+𝑏(𝑖)) 계산 후 원소별 곱 결과를 기억셀에 추가
- σ𝜎 - input 게이트
- i - 출력
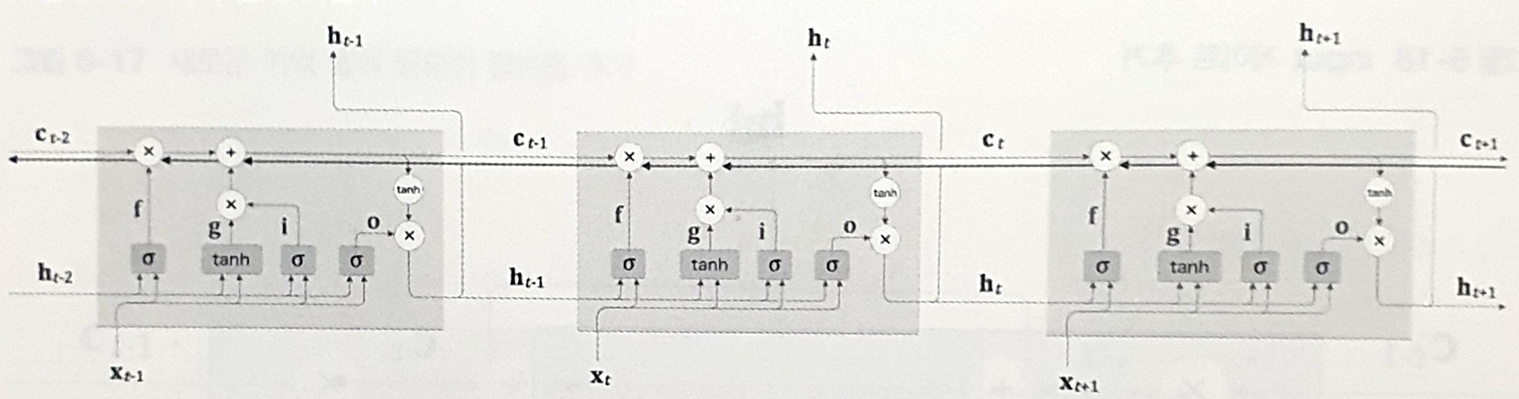
기억 셀의 역전파
+ 노드 - 상류에서의 기울기를 그대로 전달
x 노드 - 원소별 곱(아마다르 곱)을 계산 -> 기울기 소실, 기울기 폭발 방지
6.3 LSTM 구현
LSTM(Long Short -Term Memory) - 직영하면 장,단기 메모리로 단기기억을 긴 시간 지속한다는 의미로 사용
최초 한 단계 처리 후 T개의 단계를 한번에 처리하는 Time LSTM 클래스 구현
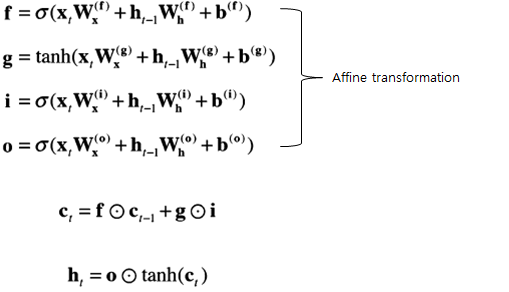
LSTM에서 수행하는 계산식
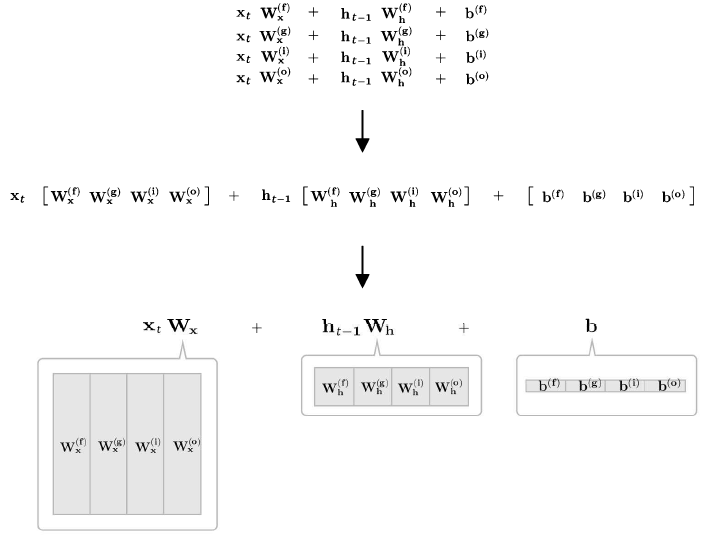
각 식의 가중치들을 한번의 affine 변환으로 계산
위 예에서는 4개의 가중치, 편향을 하나로 모았다(개별적 수행으로 4번의 계산을 affine 변환을 통해 1번의 계산으로) -> 계산 속도 향상
* Affine transformation - 행렬 변환, 평행 이동(편향)을 결합한 형태
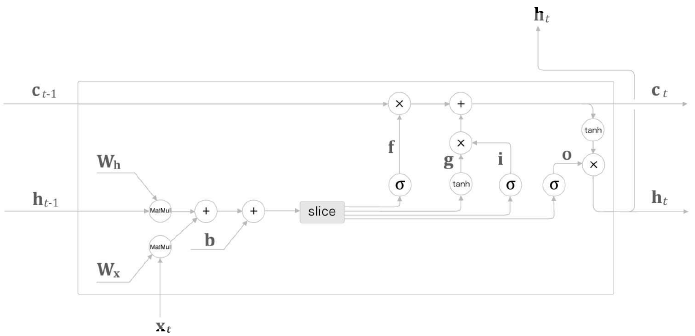
4개의 가중치를 모아 affine변환을 수행한 LSTM 계산 그래프
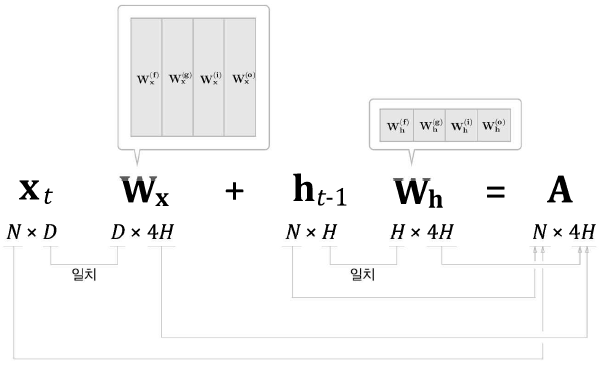
affine 변환 시의 형상
LSTM - 4개의 가중치를 하나로 보관 -> 매개변수 Wx,Wh,b𝑊𝑥,𝑊ℎ,𝑏 총 3개 관리
RNN - 매개변수 Wx,Wh,b𝑊𝑥,𝑊ℎ,𝑏 3개의 매개변수 관리
LSTM, RNN - 매개변수의 수는 같다 / 형상이 다르다
Time LSTM 구현
class LSTM:
def __init__(self, Wx, Wh, b): # 가중치 Wx, Wh, 편향 b 초기화
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
self.h, self.c = None, None
self.dh = None
self.stateful = stateful
def forward(self, x, h_prev, c_prev): # h_prev - 이전 시각 hidden state, x - 현 시각, c_prev - 이전 시각 memory cell
Wx, Wh, b = self.params
N, T, D = xs.shape
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, T, H), dtype = 'f')
if not self.stateful or self.h is None:
self.h = np.zeros((N,H), dtype = 'f')
if not self.stateful or self.c is None:
self.c = np.zeros((N,H), dtype ='f')
for t in range(T):
layer = LSTM(*self.params)
self.h, self.c = layer.forward(xs[:,t,:], self.h, self.c)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype = 'f')
dh, dc = 0,0
grads = [0,0,0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h, c=None):
self.h, self.c = h, c
def reset_state(self):
self.h, self.c = None, None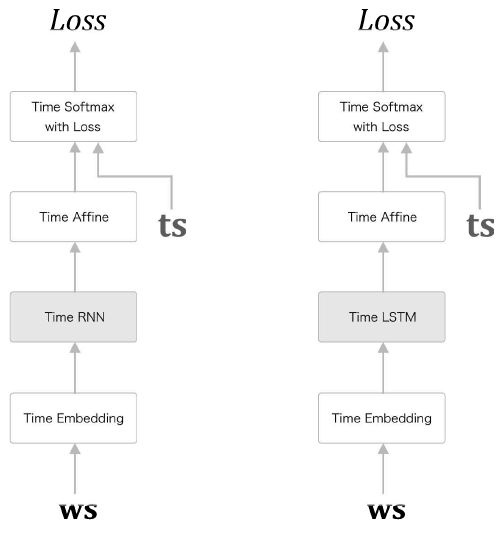
Time RNN, Time LSTM 모델
현 RNNLM의 개선점
- LSTM 계층 다층화 (LSTM 계층을 깊게 쌓음)
- -> 정확도 향상
- overfitting을 막기위한 normalization의 일종 dropout
- 변형 드롭아웃의 예 (mask - 통과 차단을 결정하는 binary 형태의 무작위 패턴, 같은 계층의 드롭아웃끼리 마스크를 고정하여 정보의 손실을 최소화 하는 방법)
- dropout의 경우 깊이 방향(시간축과 독립적인)으로 하여 정보 손실 최소화
- 가중치 공유(weight tying)
- 예( Embedding 계층, Sfotmax 앞의 Affine 계층의 가중치를 공유)
- 학습하는 매개변수를 줄여(과적합을 줄여) 정확도를 향상
- 예( Embedding 계층, Sfotmax 앞의 Affine 계층의 가중치를 공유)
기존 RNN의 문제점
- 기울기 소실
- 해결방안 - 기존 RNN에 게이트(input, forget, output 등) 추가
'독서 > 밑바닥부터 시작하는 딥러닝 2' 카테고리의 다른 글
| [밑바닥부터 시작하는 딥러닝 2]Chapter 8. 어텐션 (0) | 2024.08.11 |
|---|---|
| [밑바닥부터 시작하는 딥러닝 2]Chapter 7. RNN을 사용한 문장 생성 (0) | 2024.08.06 |
| [밑바닥부터 시작하는 딥러닝 2] Chapter 5. 순환 신경망(RNN) (6) | 2024.07.23 |
| [밑바닥부터 시작하는 딥러닝 2] Chapter 4. word2vec 속도개선 (0) | 2024.07.14 |
| [밑바닥부터 시작하는 딥러닝 2] Chapter 3. word2vec (0) | 2024.07.07 |